前言
Hadoop 的三大核心是有:HDFS、MapReduce、YARN:
- 分布式文件系统 HDFS(Hadoop Distributed File System)
- 分布式计算系统 MapReduce
- 分布式资源管理系统 YARN
Hadoop 起源于 Google 的三大论文:
- GFS:Google 的分布式文件系统 Google File System
- MapReduce:Google 的 MapReduce 开源分布式并行计算框架
- BigTable:一个大型的分布式数据库
演变关系:
- GFS ---> HDFS
- Google MapReduce ---> Hadoop MapReduce
- BigTable ---> HBase
Hadoop 生态圈其中几个比较重要的组件:
- HBase:来源于Google的BigTable;是一个高可靠性、高性能、面向列、可伸缩的分布式数据库。
- Hive:是一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
- ZooKeeper:来源于Google的Chubby;它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度。
- Ambari:Hadoop管理工具,可以快捷地监控、部署、管理集群。
- Sqoop:用于在Hadoop与传统的数据库间进行数据的传递。
- Mahout:一个可扩展的机器学习和数据挖掘库。
hadoop:它是一个分布式计算+分布式文件系统,前者其实就是 MapReduce,后者是 HDFS
hive:通俗的说是一个数据仓库,它支持类似sql语句的功能,你可以通过该语句完成分布式环境下的计算功能,hive会把语句转换成MapReduce,然后交给hadoop执行。这里的计算,仅限于查找和分析,而不是更新、增加和删除。
它的优势是对历史数据进行处理,用时下流行的说法是离线计算,因为它的底层是MapReduce,MapReduce在实时计算上性能很差。它的做法是把数据文件加载进来作为一个hive表(或者外部表),让你觉得你的sql操作的是传统的表。
hbase:通俗的说,hbase的作用类似于数据库,传统数据库管理的是集中的本地数据文件,而hbase基于hdfs实现对分布式数据文件的管理,比如增删改查。也就是说,hbase只是利用hadoop的hdfs帮助其管理数据的持久化文件(HFile),它跟MapReduce没任何关系。
hbase的优势在于实时计算,所有实时数据都直接存入hbase中,客户端通过API直接访问hbase,实现实时计算。由于它使用的是nosql,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟MapReduce的区别。
一、准备
1.下载 jdk-8u341-linux-x64.tar.gz
2.下载 hadoop-2.6.5.tar.gz
3.修改别名
配置 /etc/hostname 文件
node00014.配置/etc/hosts
为了方便,配置映射信息,本机 ip 为 172.17.0.2 对应与 node0001
172.17.0.2 node0001二、安装hadoop
1.解压
把 jdk-8u341-linux-x64.tar.gz 和 hadoop-2.6.5.tar.gz 解压到 /opt/ 目录下
tar -xf jdk-8u341-linux-x64.tar.gz -C /opt/
tar -xf hadoop-2.6.5.tar.gz -C /opt/2.修改配置文件的JAVA_HOME
在 /opt/hadoop-2.6.5/etc/hadoop/ 目录下,有 hadoop-env.sh、mapred-env.sh、yarn-env.sh 文件,修改其 JAVA_HOME 的路径
export JAVA_HOME=/opt/jdk1.8.0_341/3.配置主节点信息,dir目录信息
打开 /opt/hadoop-2.6.5/etc/hadoop/core-site.xml 文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node0001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/pseudo</value>
</property>
</configuration>4.配置从节点信息
打开 /opt/hadoop-2.6.5/etc/hadoop/slaves 文件
node00015.配置副本数量、及secondary
打开 /opt/hadoop-2.6.5/etc/hadoop/hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node0001:50090</value>
</property>
</configuration>三、配置 ssh
node0001 安装 openssh-client,生成公钥
ssh-keygen -t rsanode0001 安装 openssh-server,开启 sshserver 服务
把 node0001 的 ssh 公钥追加到 node0001 .ssh 的 authorized_keys 文件中
(node0001 可以免密登陆 node0001)
四、使用
1.格式化
hdfs namenode -format格式化成功
root@node0001:/opt/hadoop-2.6.5/bin# ./hdfs namenode -format
23/10/11 05:55:15 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node0001/172.17.0.2
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
23/10/11 05:55:16 INFO util.GSet: Computing capacity for map NameNodeRetryCache
23/10/11 05:55:16 INFO util.GSet: VM type = 64-bit
23/10/11 05:55:16 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
23/10/11 05:55:16 INFO util.GSet: capacity = 2^15 = 32768 entries
23/10/11 05:55:16 INFO namenode.NNConf: ACLs enabled? false
23/10/11 05:55:16 INFO namenode.NNConf: XAttrs enabled? true
23/10/11 05:55:16 INFO namenode.NNConf: Maximum size of an xattr: 16384
23/10/11 05:55:16 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1807366575-172.17.0.2-1697003716159
23/10/11 05:55:16 INFO common.Storage: Storage directory /var/hadoop/pseudo/dfs/name has been successfully formatted.
23/10/11 05:55:16 INFO namenode.FSImageFormatProtobuf: Saving image file /var/hadoop/pseudo/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
23/10/11 05:55:16 INFO namenode.FSImageFormatProtobuf: Image file /var/hadoop/pseudo/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
23/10/11 05:55:16 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
23/10/11 05:55:16 INFO util.ExitUtil: Exiting with status 0
23/10/11 05:55:16 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node0001/172.17.0.2
************************************************************/会在 /var/hadoop/pseudo 下生成数据
root@node0001:/var/hadoop/pseudo# ls
dfs2.启动
使用 start-dfs.sh 启动 hadoop
start-dfs.sh启动成功
root@node0001:/opt/hadoop-2.6.5/sbin# ./start-dfs.sh
Starting namenodes on [node0001]
node0001: starting namenode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-namenode-node0001.out
node0001: starting datanode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-datanode-node0001.out
Starting secondary namenodes [node0001]
node0001: starting secondarynamenode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-secondarynamenode-node0001.out使用jps,查看当前java进程
root@node0001:/opt/jdk1.8.0_341/bin# ./jps
5904 Jps
5618 DataNode
5771 SecondaryNameNode
5502 NameNode在浏览器输入 node0001:50070 可以看到界面
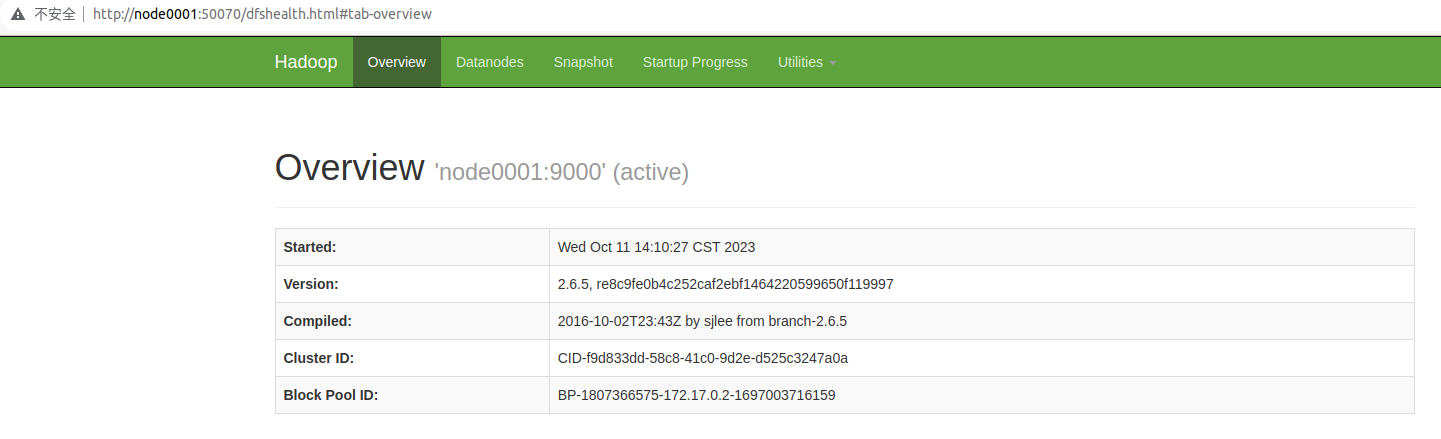
3.使用 hdfs 建立目录
建立目录 /user/roots
hdfs dfs -mkdir -p /user/rootroot@node0001:/opt/hadoop-2.6.5/bin# ./hdfs dfs -mkdir -p /user/root4.上传文件
把文件上传到 /user/root
hdfs dfs -put /root/test.tar.gz /user/root
hdfs dfs -put /root/test1.tar.gz /user/root原文件大小 141.3 MB
root@node0001:/opt/hadoop-2.6.5/bin# ./hdfs dfs -put /root/test.tar.gz /user/root
root@node0001:/opt/hadoop-2.6.5/bin# ./hdfs dfs -put /root/test1.tar.gz /user/root在 node0001:50070 可以查看上传的文件
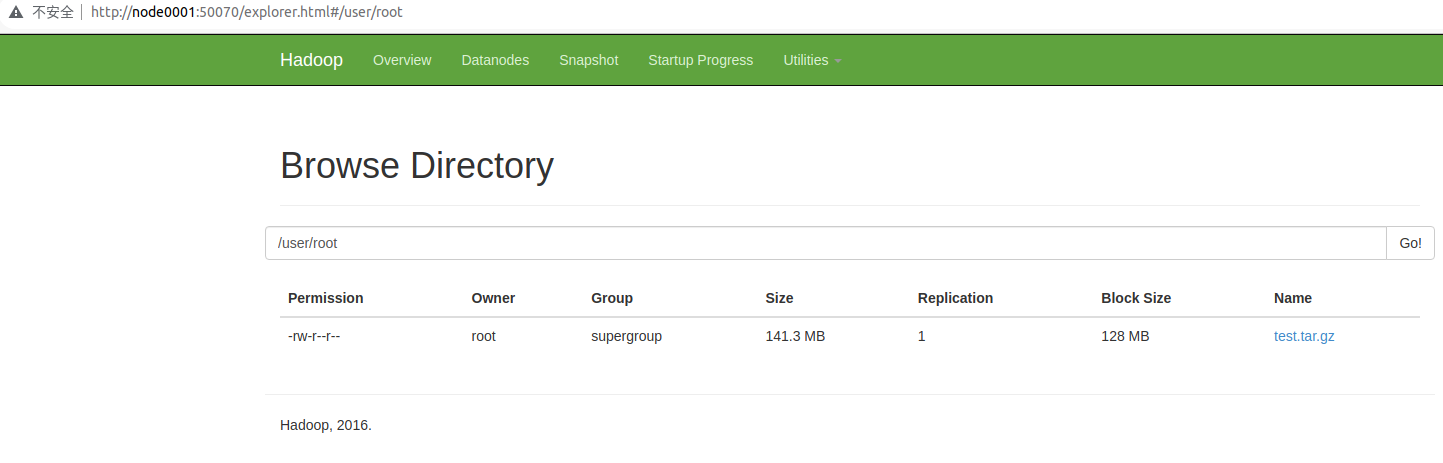
5.数据位置
原文件大小 141.3 MB
node0001 上 namenode 信息在:
root@node0001:/var/hadoop/pseudo/dfs/name/current# ls -lh
total 1.1M
-rw-r--r-- 1 root root 202 Oct 11 17:05 VERSION
-rw-r--r-- 1 root root 189 Oct 11 17:06 edits_0000000000000000001-0000000000000000004
-rw-r--r-- 1 root root 1.0M Oct 11 17:06 edits_inprogress_0000000000000000005
-rw-r--r-- 1 root root 321 Oct 11 17:05 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Oct 11 17:05 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 460 Oct 11 17:06 fsimage_0000000000000000004
-rw-r--r-- 1 root root 62 Oct 11 17:06 fsimage_0000000000000000004.md5
-rw-r--r-- 1 root root 2 Oct 11 17:06 seen_txidnode0001 上 datanode 信息在:
root@node0001:/var/hadoop/pseudo/dfs/data/current/BP-1791117656-172.17.0.2-1697015111310/current/finalized/subdir0/subdir0# ls -lh
total 285M
-rw-r--r-- 1 root root 128M Oct 11 17:06 blk_1073741825
-rw-r--r-- 1 root root 1.1M Oct 11 17:06 blk_1073741825_1001.meta
-rw-r--r-- 1 root root 14M Oct 11 17:06 blk_1073741826
-rw-r--r-- 1 root root 107K Oct 11 17:06 blk_1073741826_1002.meta
-rw-r--r-- 1 root root 128M Oct 11 17:06 blk_1073741827
-rw-r--r-- 1 root root 1.1M Oct 11 17:06 blk_1073741827_1003.meta
-rw-r--r-- 1 root root 14M Oct 11 17:06 blk_1073741828
-rw-r--r-- 1 root root 107K Oct 11 17:06 blk_1073741828_1004.meta6.关闭
使用 stop-dfs.sh 关闭 hadoop
stop-dfs.sh关闭成功
root@node0001:/opt/hadoop-2.6.5/sbin# ./stop-dfs.sh
Stopping namenodes on [node0001]
node0001: stopping namenode
node0001: stopping datanode
Stopping secondary namenodes [node0001]
node0001: stopping secondarynamenode