一、MergeTree
MergeTree系列会合并分区。MergeTree主键允许存在重复数据,ReplacingMergeTree可以去重。
1.创建表
CREATE TABLE student
(
`id` Int64 COMMENT '编号',
`name` String COMMENT '名称',
`subject` String COMMENT '科目',
`score` Int64 COMMENT '分数',
`created_at` DateTime DEFAULT NOW() COMMENT '创建时间',
`updated_at` DateTime DEFAULT NOW() COMMENT '修改时间'
)
ENGINE = MergeTree()
ORDER BY (id, name, subject)
PARTITION BY subject;必填项:
- ENGINE:创建MergeTree的表引擎指定ENGINE = MergeTree()
- ORDER BY语句:sorting key 排序键,用于指定在一个数据片段内数据以何种标准排序。默认情况下是主键primary key与排序键相同。排序键可以单个列字段,也可以多个列字段。
选填项:
- PARTITION BY :分区键,用于指定表数据以何种标准进行分区。分区键可以单个列字段,也可以是通过元祖形式使用的多个列字段,还可以支持使用列表达式。若不声明分区键则clickhouse会生成一个名为all的分区。合理使用分区 可以有效减少查询数据文件的扫描范围。
- primary key:主键,声明后会按照主键字段生成一级索引,用于加速表查询。默认情况下主键与排序键相同,所以通常直接使用order by 指定主键,无须刻意通过primary key声明。在一般情况下,在单个数据片段内 数据与一级索引以相同的规则升序排列。
注意:order by 和primary key定义有差异的应用场景是SummingMergeTree引擎。
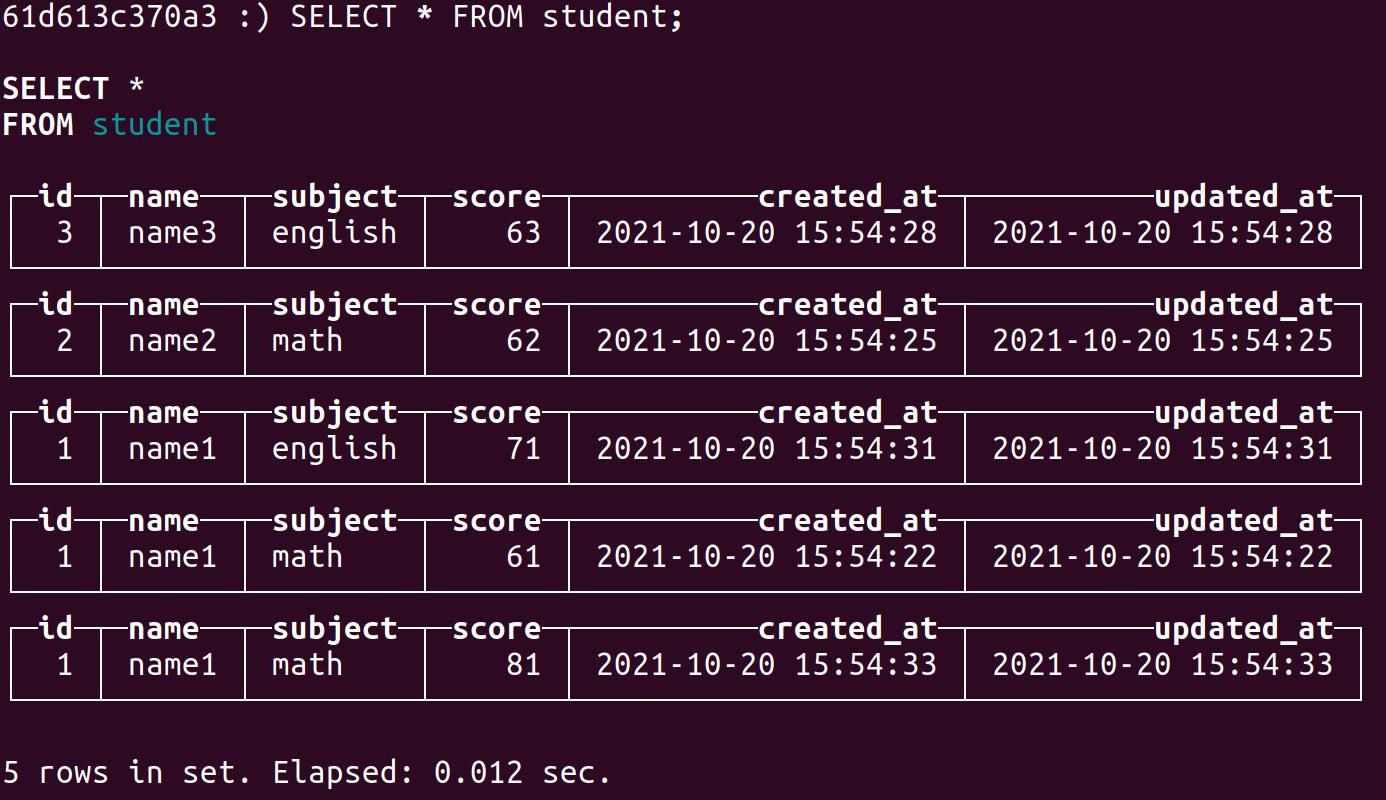
2.插入数据
INSERT INTO student (id, name, subject, score) VALUES(1, 'name1', 'math', 61);
INSERT INTO student (id, name, subject, score) VALUES(2, 'name2', 'math', 62);
INSERT INTO student (id, name, subject, score) VALUES(3, 'name3', 'english', 63);
INSERT INTO student (id, name, subject, score) VALUES(1, 'name1', 'english', 71);
INSERT INTO student (id, name, subject, score) VALUES(1, 'name1', 'math', 81);3.查看数据
查看数据:
执行合并:
OPTIMIZE 只是促进合并,并不代表会立刻合并。如果不执行OPTIMIZE,clickhouse会在空闲的时候执行合并。
OPTIMIZE TABLE student;合并后数据:
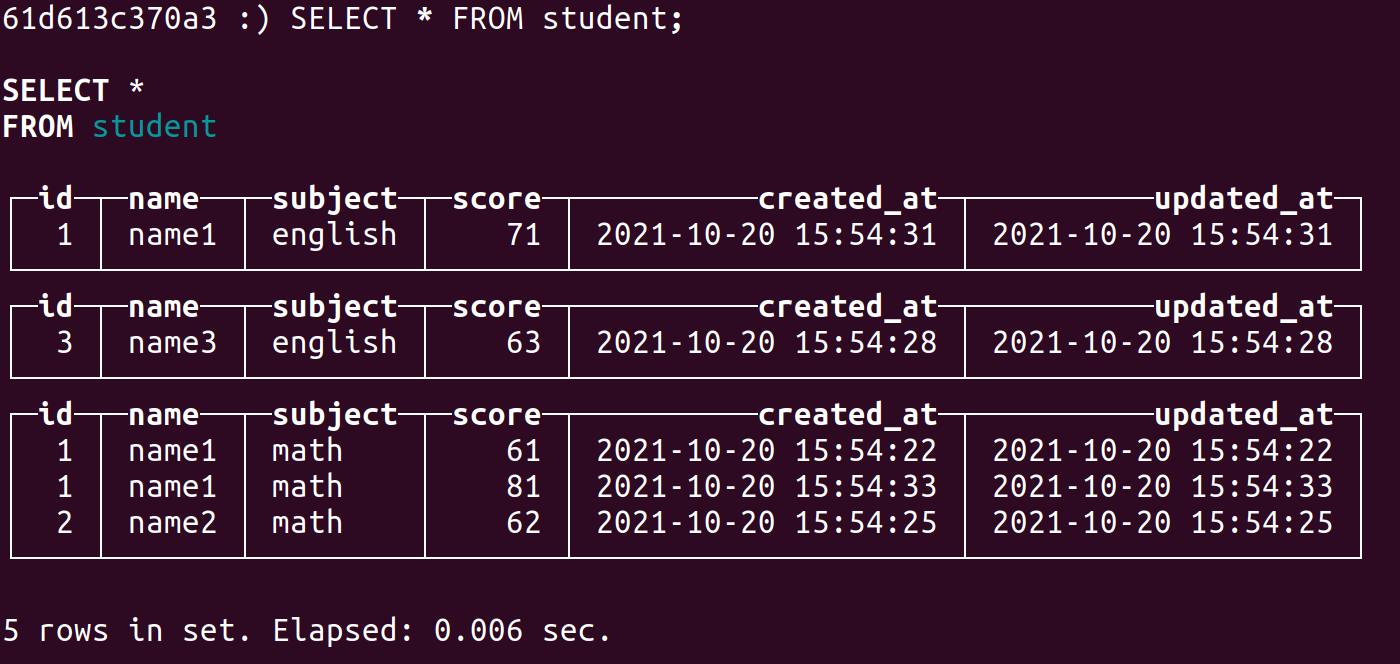
过段时间,完成全部的合并:
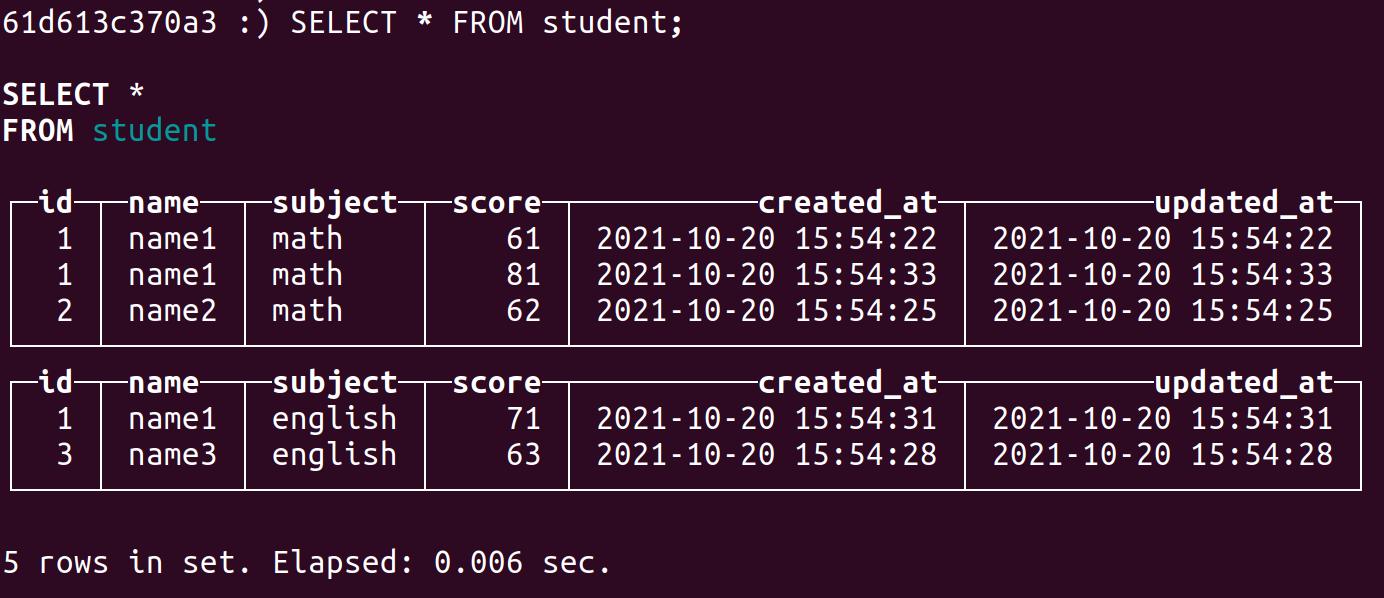
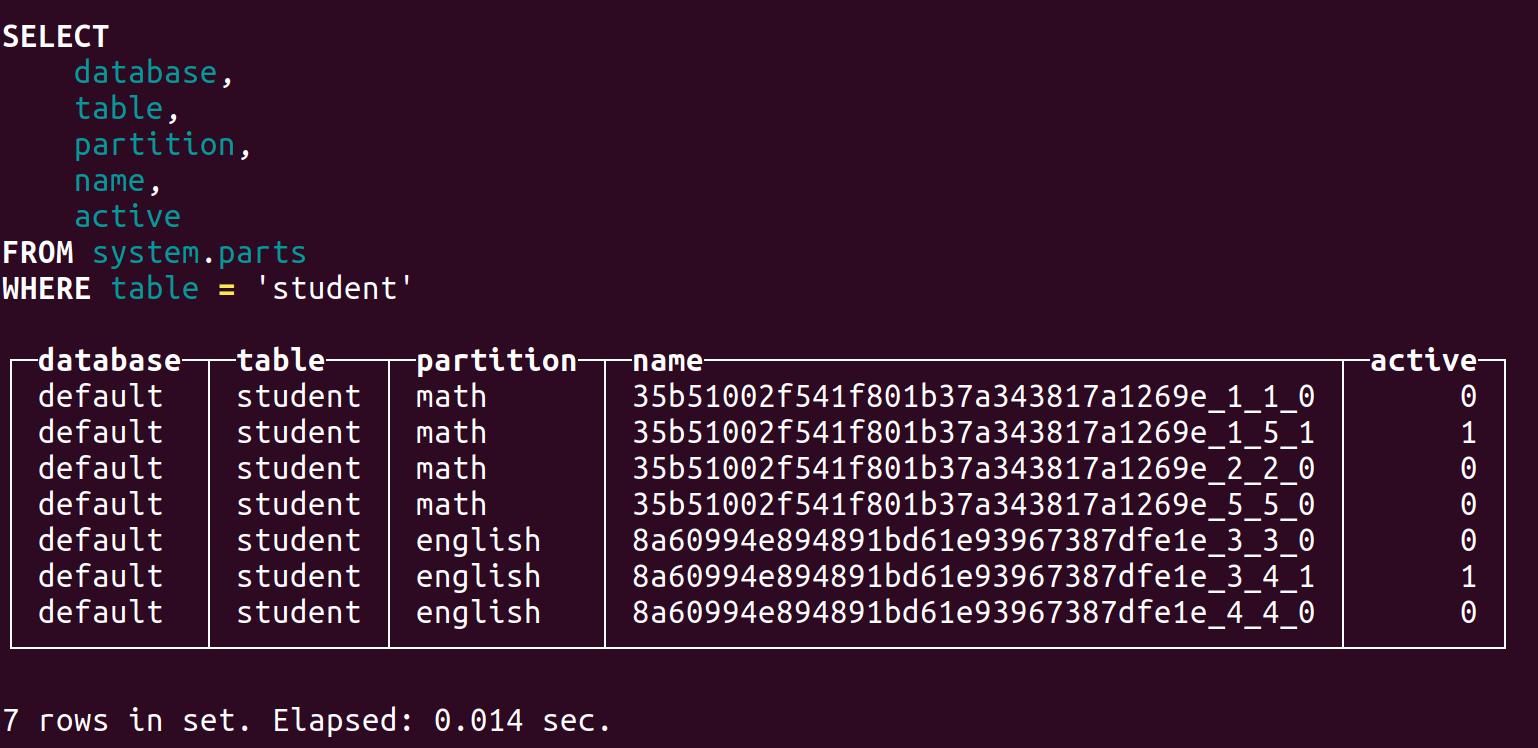
查看分区:
二、ReplacingMergeTree
ReplacingMergeTree数据合并阶段用替代方式合并排序键相同的数据,用于保证存储空间,不保证数据不重复。
1.创建表
CREATE TABLE student_rmt
(
`id` Int64 COMMENT '编号',
`name` String COMMENT '名称',
`subject` String COMMENT '科目',
`score` Int64 COMMENT '分数',
`created_at` DateTime DEFAULT NOW() COMMENT '创建时间',
`updated_at` DateTime DEFAULT NOW() COMMENT '修改时间'
)
ENGINE = ReplacingMergeTree(created_at)
ORDER BY (id, name, subject)
PARTITION BY subject;ReplacingMergeTree(ver) 的参数
- ver — 版本列。类型为 UInt*, Date 或 DateTime。可选参数。在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:如果 ver 列未指定,保留最后一条;如果 ver 列已指定,保留 ver 值最大的版本。
2.插入数据
INSERT INTO student_rmt (id, name, subject, score) VALUES(1, 'name1', 'math', 61);
INSERT INTO student_rmt (id, name, subject, score) VALUES(2, 'name2', 'math', 62);
INSERT INTO student_rmt (id, name, subject, score) VALUES(3, 'name3', 'english', 63);
INSERT INTO student_rmt (id, name, subject, score) VALUES(1, 'name1', 'english', 71);
INSERT INTO student_rmt (id, name, subject, score) VALUES(1, 'name1', 'math', 81);3.查看数据
执行合并:
OPTIMIZE TABLE student_rmt;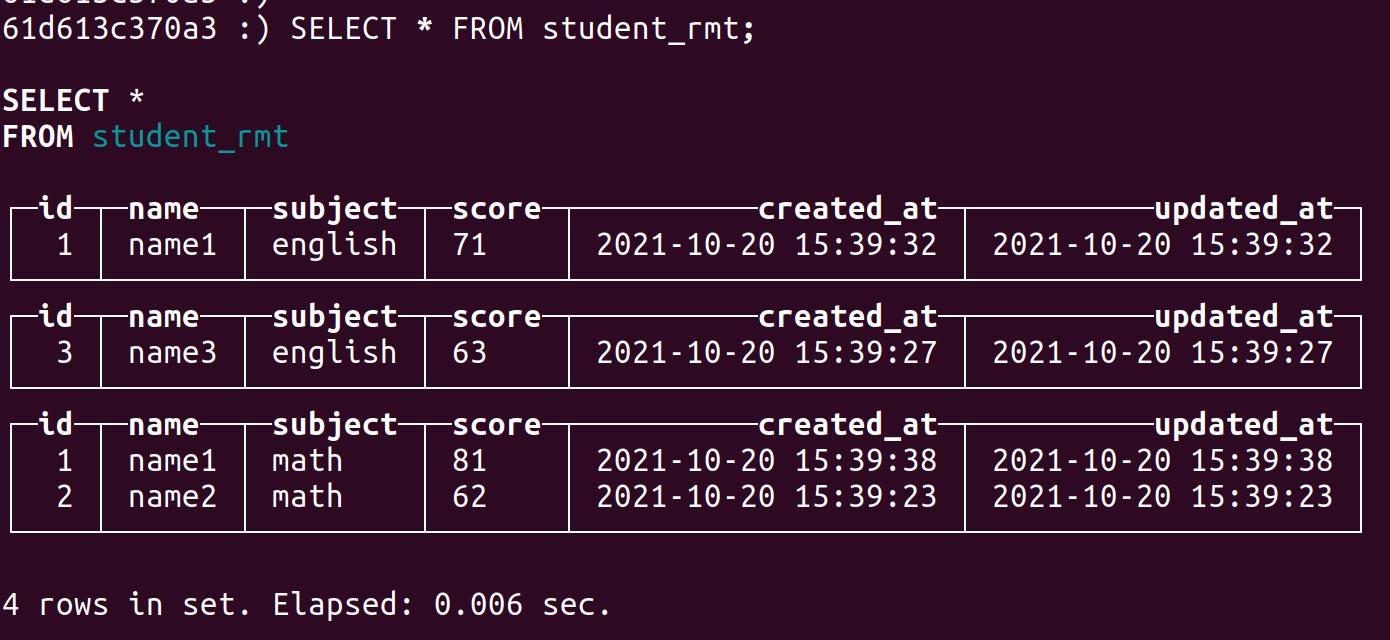
三、CollapsingMergeTree
CollapsingMergeTree就是一种通过以增代删的思路。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除,注意严格的写入顺序,先1后-1。
1.创建表
CREATE TABLE student_cmt
(
`id` Int64 COMMENT '编号',
`name` String COMMENT '名称',
`subject` String COMMENT '科目',
`score` Int64 COMMENT '分数',
`created_at` DateTime DEFAULT NOW() COMMENT '创建时间',
`updated_at` DateTime DEFAULT NOW() COMMENT '修改时间',
`sign` Int8 DEFAULT 1
)
ENGINE = CollapsingMergeTree(sign)
ORDER BY (id, name, subject)
PARTITION BY subject;sign的值为1或-1,若是插入其他值,执行合并的时候会报错。
对于,排序键相同且sign相同的数据,会进行替代,sign为1,保留最新的数据;sign为-1,保留最旧的数据。
CollapsingMergeTree对于写入数据的顺序有着严格要求,否则导致无法正常折叠。先写入1的数据,再写入-1的数据。执行合并时,先执行抵消最旧的数据,再进行替换。
如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree的工作机制就会出现问题。但是可以通过VersionedCollapsingMergeTree的表引擎得到解决。
2.插入数据
INSERT INTO student_cmt (id, name, subject, score, sign) VALUES(1, 'name1', 'math', 61, 1);
INSERT INTO student_cmt (id, name, subject, score, sign) VALUES(2, 'name2', 'math', 62, 1);
INSERT INTO student_cmt (id, name, subject, score, sign) VALUES(3, 'name3', 'english', 63, 1);
INSERT INTO student_cmt (id, name, subject, score, sign) VALUES(1, 'name1', 'english', 71, 1);
INSERT INTO student_cmt (id, name, subject, score, sign) VALUES(1, 'name1', 'math', 81, 1);
INSERT INTO student_cmt (id, name, subject, score, sign) VALUES(1, 'name1', 'math', 91, -1);3.查看数据
执行合并:
OPTIMIZE TABLE student_cmt;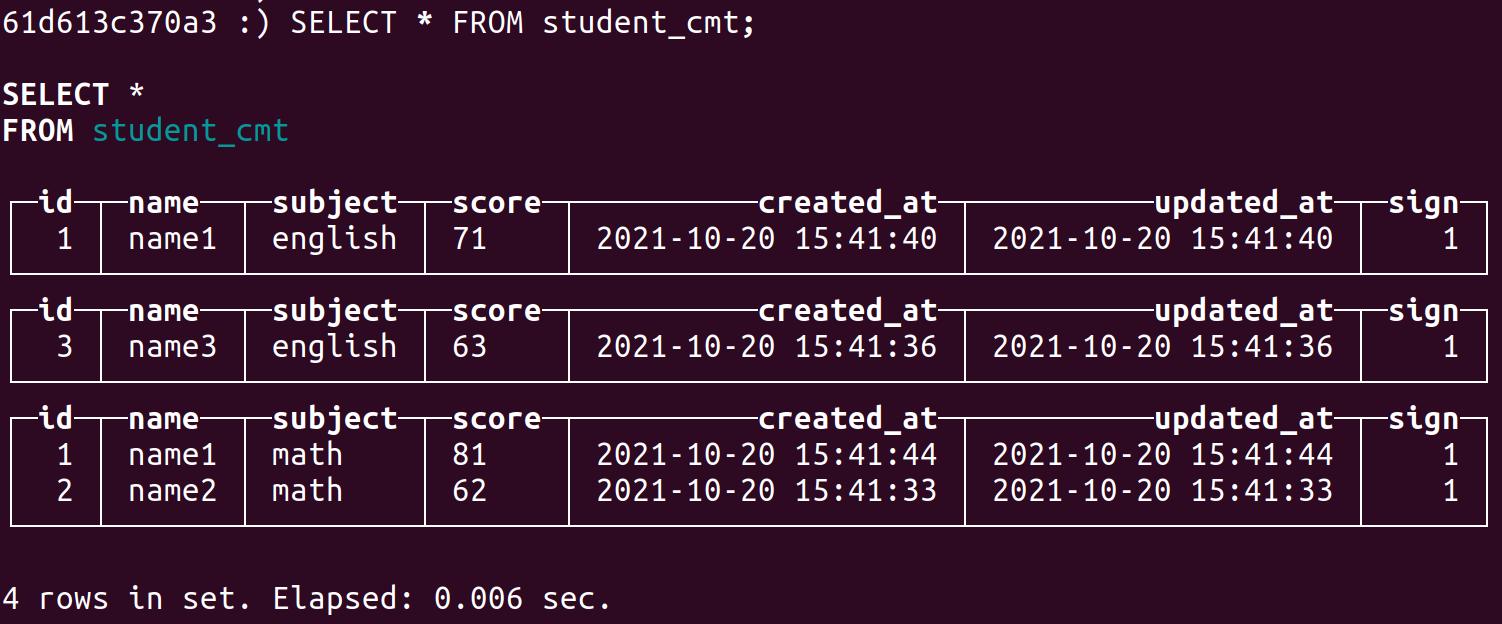
四、VersionedCollapsingMergeTree
VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。
消除排序键相同且版本相同的,sign为1和-1的一对数据。
1.创建表
CREATE TABLE student_vcmt
(
`id` Int64 COMMENT '编号',
`name` String COMMENT '名称',
`subject` String COMMENT '科目',
`score` Int64 COMMENT '分数',
`created_at` DateTime DEFAULT NOW() COMMENT '创建时间',
`updated_at` DateTime DEFAULT NOW() COMMENT '修改时间',
`sign` Int8 DEFAULT 1,
`version` Int8 DEFAULT 1
)
ENGINE = VersionedCollapsingMergeTree(sign, version)
ORDER BY (id, name, subject)
PARTITION BY subject;2.插入数据
INSERT INTO student_vcmt (id, name, subject, score, sign, version) VALUES(1, 'name1', 'math', 61, -1, 1);
INSERT INTO student_vcmt (id, name, subject, score, sign, version) VALUES(2, 'name2', 'math', 62, 1, 1);
INSERT INTO student_vcmt (id, name, subject, score, sign, version) VALUES(3, 'name3', 'english', 63, 1, 1);
INSERT INTO student_vcmt (id, name, subject, score, sign, version) VALUES(1, 'name1', 'english', 71, 1, 1);
INSERT INTO student_vcmt (id, name, subject, score, sign, version) VALUES(1, 'name1', 'math', 81, 1, 1);
INSERT INTO student_vcmt (id, name, subject, score, sign, version) VALUES(1, 'name1', 'math', 91, 1, 1);3.查看数据
执行合并:
OPTIMIZE TABLE student_vcmt;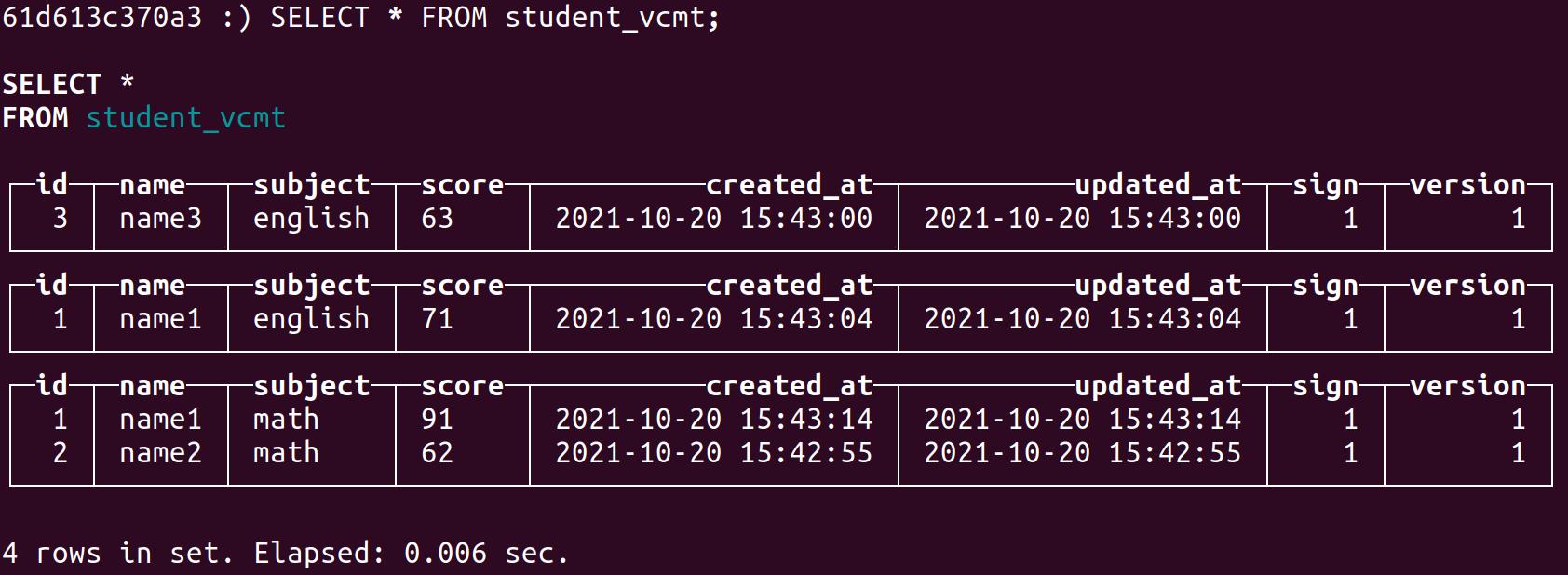
五、AggregatingMergeTree
AggregatingMergeTree主要用于创建物化视图。物化视图可以理解为预计算,聚合函数的值提前在物化视图中已经计算好了,查询的时候就直接拿值就好了,提高了查询的速度,当然物化视图也占用本地磁盘空间,相当于空间换时间,并且源表数据变化物化视图也会跟着修改,所以要尽可能减少修改操作。
1.创建表
CREATE MATERIALIZED VIEW mv_student
ENGINE = AggregatingMergeTree()
PARTITION BY (subject)
ORDER BY (subject)
POPULATE AS
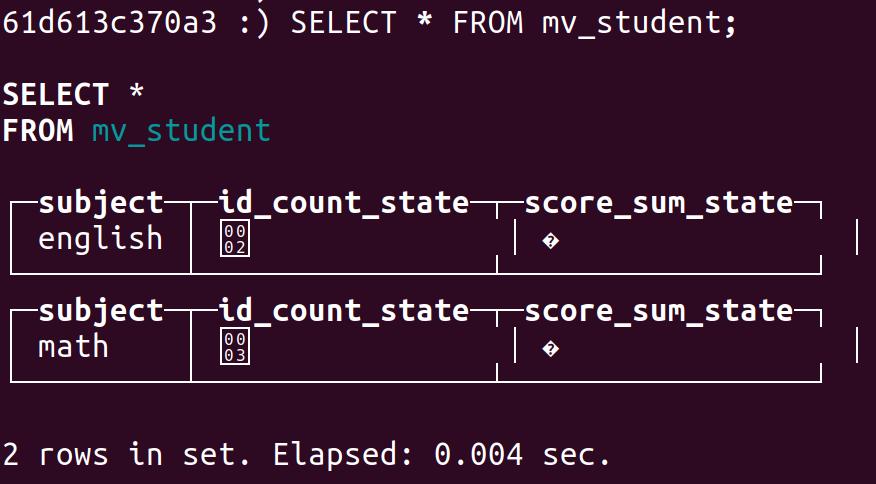
SELECT
subject,
countState(id) AS id_count_state,
sumState(score) AS score_sum_state
FROM student
GROUP BY subject;2.查看数据
查询物化视图的sql
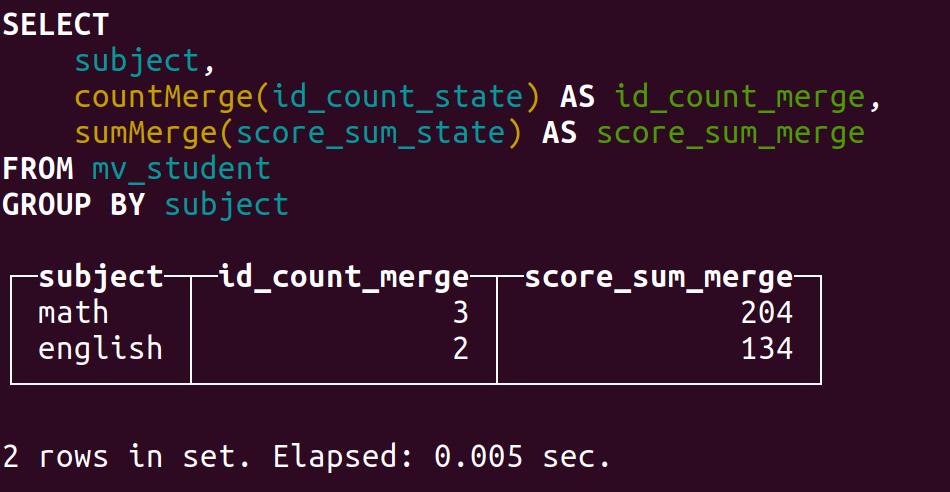
SELECT
subject,
countMerge(id_count_state) AS id_count_merge,
sumMerge(score_sum_state) AS score_sum_merge
FROM mv_student
GROUP BY subject;