一、概述
实现高可用,但是没有分区
实现监控和自动故障恢复功能
二、搭建
1.拉取镜像
docker pull redis:6.0.102.创建容器
创建 6 个 docker 容器
| 容器 | ip | 角色 |
|---|---|---|
| redis-6381 | 172.17.0.2 | 主节点 |
| redis-6382 | 172.17.0.3 | 从节点 |
| redis-6383 | 172.17.0.4 | 从节点 |
| redis-6384 | 172.17.0.5 | sentinel 节点 |
| redis-6385 | 172.17.0.6 | sentinel 节点 |
| redis-6386 | 172.17.0.7 | sentinel 节点 |
对于 主从节点,使用 redis-server 命令;对于 sentinel 节点,使用 redis-sentinel 命令
docker run -d --privileged=true -p 6381:6379 --name redis-6381 redis:6.0.10 redis-server /data/redis.conf
docker run -d --privileged=true -p 6382:6379 --name redis-6382 redis:6.0.10 redis-server /data/redis.conf
docker run -d --privileged=true -p 6383:6379 --name redis-6383 redis:6.0.10 redis-server /data/redis.conf
docker run -d --privileged=true -p 6384:6379 --name redis-6384 redis:6.0.10 redis-sentinel /data/redis.conf
docker run -d --privileged=true -p 6385:6379 --name redis-6385 redis:6.0.10 redis-sentinel /data/redis.conf
docker run -d --privileged=true -p 6386:6379 --name redis-6386 redis:6.0.10 redis-sentinel /data/redis.conf此时,是启动失败的,因为容器内没有 redis 配置文件
3.修改配置
主从节点配置文件 redis.conf 如下:
# bind 127.0.0.1
port 6379
pidfile /var/run/redis_6379.pid
logfile ""
dbfilename dump.rdb
dir ./
protected-mode nosentinel 节点配置文件 redis.conf 如下:
# bind 127.0.0.1
port 6379
pidfile /var/run/redis_6379.pid
logfile ""
dbfilename dump.rdb
dir ./
protected-mode no
# 当前Sentinel节点监控 172.17.0.2 :6379 这个主节点
# 2代表判断主节点失败至少需要2个Sentinel节点节点同意
# mymaster 是主节点的别名
sentinel monitor mymaster 172.17.0.2 6379 2
# 每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过10000毫秒10s且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster 10000
# 当Sentinel节点集合对主节点故障判定达成一致时,Sentinel 领导者节点会做故障转移操作,选出新的主节点,
# 原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为 1
sentinel parallel-syncs mymaster 1
# 故障转移超时时间为30000毫秒
sentinel failover-timeout mymaster 30000使用 docker cp 命令把配置文件从宿主机复制到容器中
4.启动容器
docker start redis-6381 redis-6382 redis-6383 redis-6384 redis-6385 redis-6386
5.配置主从节点
使用 replicaof 配置主从节点,主节点是 172.17.0.2,从节点是 172.17.0.3 和 172.17.0.4
root@c04509c0752e:/data# redis-cli -h 172.17.0.3
172.17.0.3:6379> replicaof 172.17.0.2 6379
OK
172.17.0.3:6379> exit
root@c04509c0752e:/data# redis-cli -h 172.17.0.4
172.17.0.4:6379> replicaof 172.17.0.2 6379
OK查看主从节点:
root@c04509c0752e:/data# redis-cli -h 172.17.0.2 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.17.0.3,port=6379,state=online,offset=405572,lag=1
slave1:ip=172.17.0.4,port=6379,state=online,offset=405572,lag=0
master_replid:7aea66446bef06c6c4b0dbcfabf4cd5f94efd935
master_replid2:28ed50a921a3f4e54b3be1037e53e10a5caf24a4
master_repl_offset:405572
second_repl_offset:393009
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:120388
repl_backlog_histlen:285185
root@c04509c0752e:/data# 查看 sentinel:
root@27094fd87004:/data# redis-cli -h 172.17.0.5 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.17.0.2:6379,slaves=2,sentinels=3
root@27094fd87004:/data#如果主节点挂掉,sentinel 会进行选举一个从节点为主节点;如果挂掉的节点上线,此时这个节点是从节点
三、 redis 主从复制原理
1.全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
2.增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
3.判断全量与增量同步
Redis在2.8之后对从服务器重连后的数据状态同步进行了改进。改进的方向是减少全量同步(full resynchronizaztion)的发生,尽可能使用增量同步(partial resynchronization)。
在2.8版本之后使用psync命令代替了sync命令来执行同步操作,psync命令同时具备全量同步和增量同步的功能:
- 全量同步与上一版本(sync)一致
- 增量同步中对于断线重连后的复制,会根据情况采取不同措施;如果条件允许,仍然只发送从服务缺失的部分数据。
4.psync 的实现
Redis为了实现从服务器断线重连后的增量同步,增加了三个辅助参数:
- 复制偏移量(replication offset)
- 积压缓冲区(replication backlog)
- 服务器运行id(run id)
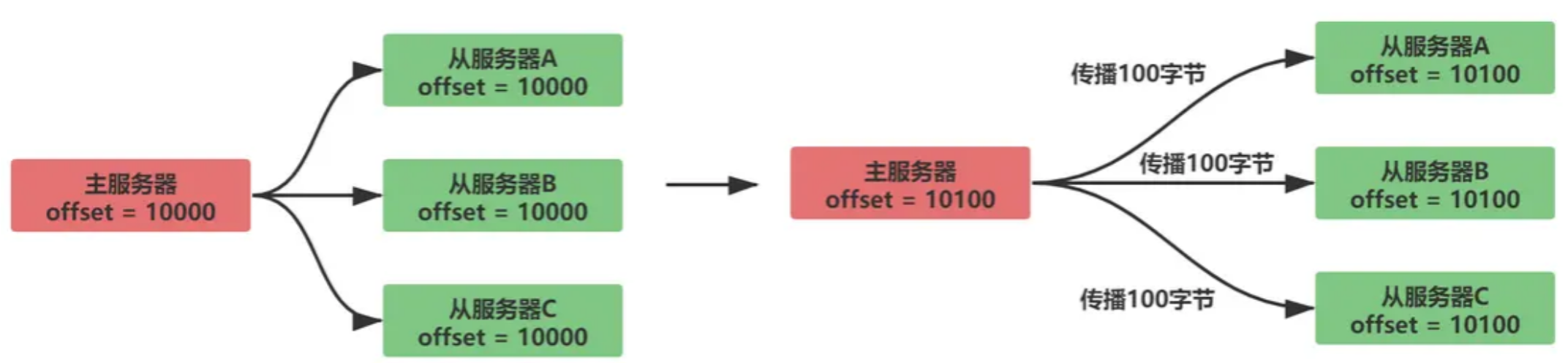
复制偏移量:
在主服务器和从服务器内都会维护一个复制偏移量
- 主服务器向从服务发送数据,传播N个字节的数据,主服务的复制偏移量增加N
- 从服务器接收主服务器发送的数据,接收N个字节的数据,从服务器的复制偏移量增加N
复制积压缓冲区:
复制积压缓冲区是一个固定长度的队列,默认为1MB大小。当主服务器数据状态发生改变,主服务器将数据同步给从服务器的同时会另存一份到复制积压缓冲区中。
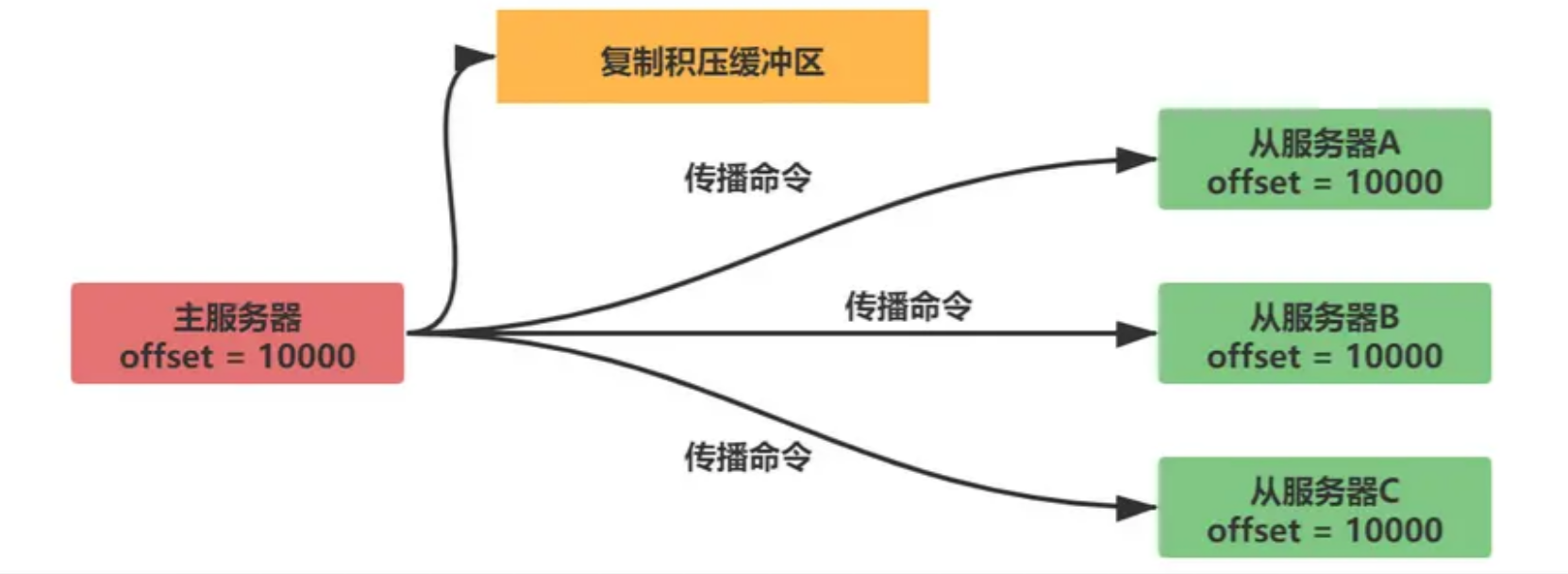
复制积压缓冲区为了能和偏移量进行匹配,它不仅存储了数据内容,还记录了每个字节对应的偏移量

当从服务器断线重连后,从服务器通过psync命令将自己的复制偏移量(offset)发送给主服务器,主服务器便可通过这个偏移量来判断进行增量传播还是全量同步。
- 如果偏移量offset+1的数据仍然在复制积压缓冲区中,那么进行增量同步操作
- 反之进行全量同步操作,与sync一致
Redis的复制积压缓冲区的大小默认为1MB,如果需要自定义应该如何设置呢?
很明显,我们希望能尽可能的使用增量同步,但是又不希望缓冲区占用过多的内存空间。那么我们可以通过预估Redis从服务断线后重连的时间T,Redis主服务器每秒接收的写命令的内存大小M,来设置复制积压缓冲区的大小S。
S = 2 * M * T注意这里扩大2倍是为了留有一定的余地,保证绝大部分的断线重连都能采用增量同步。
服务器运行 ID:
当主服务器宕机后,某台从服务器被选举成为新的主服务器,这种情况我们就通过比较运行ID来区分。
- 运行ID(run id)是服务器启动时自动生成的40个随机的十六进制字符串,主服务和从服务器均会生成运行ID
- 当从服务器首次同步主服务器的数据时,主服务器会发送自己的运行ID给从服务器,从服务器会保存在RDB文件中
- 当从服务器断线重连后,从服务器会向主服务器发送之前保存的主服务器运行ID,如果服务器运行ID匹配,则证明主服务器未发生更改,可以尝试进行增量同步
- 如果服务器运行ID不匹配,则进行全量同步
四、 sentinel 工作
sentinel 最主要的工作就是监视 redis 服务器,当 master 实例超出预设的时限后切换新的 master 实例。大致分为检测 master 是否主观下线、检测 master 是否客观下线、选举领头 sentinel、故障转移四个步骤。
1.三个定时任务
sentinel通过三个定时监控任务实现对各个节点的发现和监控。
- 每隔10秒,每个sentinel节点都会向主节点和从节点发送info命令获取对应节点的信息(对主节点执行info replication命令可以获取从节点的信息,所以sentinel中只需要配置主节点信息就可以获取所有从节点信息)。
- 每隔2秒,每个sentinel节点会向Redis数据节点的
_sentinel_:hello频道上发送该节点对于主节点状态的判断以及自己的信息。sentinel 连接 redis 实例时,会创建两个连接,一个是 commands 命令连接和一个 pub/sub 发布订阅连接。每个 sentinel 也会订阅_sentinel_:hello这个频道,用于接收其它sentinel发布的消息以了解其它sentinel节点对于主节点状态的判断(为主节点客观下线做依据)以及其它sentinel节点的信息(用于发现新的sentinel节点)。 - 每隔1秒,每个sentinel节点会向主节点、从节点、其它sentinel节点发送一个ping命令做心跳检测,来确认这些节点是否可达。
1.检测master是否主观下线(sdown)
sentinel 每隔1秒钟,向 sentinelRedisInstance 实例中的所有 master、slave、sentinel 发送 PING 命令,通过其他服务器的回复来判断其是否仍然在线。
# 每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过10000毫秒10s且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster 10000如果节点超过down-after-milliseconds * 10的时间。(默认是30秒)都没有进行有效回复(+PONG、-LOADING 或者 -MASTERDOWN这三种都是有效回复),sentinel节点就会对该节点做失败判定,这种行为就叫做主观下线。
2.检测master是否客观下线(odown)
当sentinel主观下线的节点是主节点时,该sentinel节点就会向其它sentinel节点发送sentinel is-master-down-by-addr(这个命令还可以用于sentinel的leader选举) 命令询问他们对主节点的判断,当大于等于quorum(这个在sentinel的配置文件中配置的,如果sentinel节点是3个,quorum就配置为2。)个的sentinel都认为主节点已经挂了,那么该sentinel节点就会对主节点进行客观下线。(所以客观下线就是大部分的sentinel都认为主节点挂了)
3.sentinel的leader选举
故障转移流程的第一步就是在 sentinel 集群选择一个 leader,由 leader 完成故障转移流程。 sentinle 通过 raft 算法,实现 sentinel 选举。
sentinel采用的分布式一致性协议是raft协议。
ratf 算法:
大体上有两个步骤:领导选举,数据复制。核心思想:先到先得,少数服从多数。
发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。
4.故障转移
故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情:
- 从原先master的slave中,选择最佳的slave作为新的master
- 让其他slave成为新的master的slave
- 继续监听旧master,如果其上线,则将其设置为新的master的slave
如何选择最佳的新Master,领头sentinel会做如下清洗和排序工作:
- 判断slave是否有下线的,如果有从slave列表中移除
- 删除5秒内未响应sentinel的INFO命令的slave
- 删除与下线主服务器断线时间超过down_after_milliseconds * 10 的所有从服务器
- 根据slave优先级slave_priority,选择优先级最高的slave作为新master
- 如果优先级相同,根据slave复制偏移量slave_repl_offset,选择偏移量最大的slave作为新master
- 如果偏移量相同,根据slave服务器运行id run id排序,选择run id最小的slave作为新master
新的master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新master)发送SLAVEOF ip port命令,使其成为新master的slave。
